最近在编程时,由于涉及到大量for循环等遍历计算,需要了解并行编程知识,于是看了下OpenMP的相关教程;
OpenMP是由OpenMP Architecture Review Board牵头提出的,并已被广泛接受,用于共享内存并行系统的多处理器程序设计的一套指导性编译处理方案(Compiler Directive) [1] 。OpenMP支持的编程语言包括C、C++和Fortran;而支持OpenMp的编译器包括Sun Compiler,GNU Compiler和Intel Compiler等。OpenMp提供了对并行算法的高层的抽象描述,程序员通过在源代码中加入专用的pragma来指明自己的意图,由此编译器可以自动将程序进行并行化,并在必要之处加入同步互斥以及通信。当选择忽略这些pragma,或者编译器不支持OpenMp时,程序又可退化为通常的程序(一般为串行),代码仍然可以正常运作,只是不能利用多线程来加速程序执行。
在用OpenMP进行并行编程时,只需要加入#pragma omp parallel语句以及后面的操作命令即可,十分简单,便于程序员操作;
下面以vs为例,介绍OpenMP的简单用法:
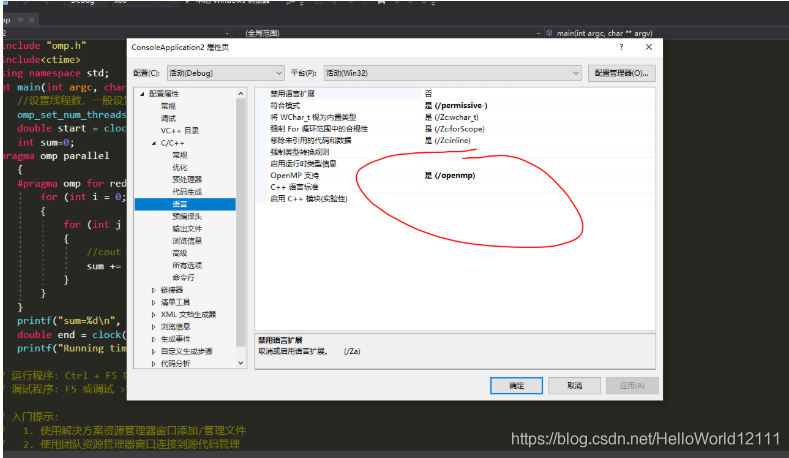
1、首先,新建项目并添加代码后,需要打开vs的OpenMP支持选项:右键项目属性-C/C+±语言-OpenMP支持
2、其次,需要添加头文件<omp.h>
3、OpenMP有很多命令可以用,比较常见的就是用于for循环来提升循环效率,即#pragma omp parallel for
4、在使用OpenMP时,要注意避免线程数据之间的竞争而导致计算出现差错,同时,亦应合理管理私有数据和公有数据
为避免线程数据之间的竞争而导致计算出现差错,下面是应用的一个例子
#include "pch.h"
#include
#include
#include "omp.h"
#include
using namespace std;
int main(int argc, char **argv) {
//设置线程数,一般设置的线程数不超过CPU核心数,这里开4个线程执行并行代码段
omp_set_num_threads(8);
double start = clock();
int sum=0;
#pragma omp parallel
{
#pragma omp for reduction(+:sum)
for (int i = 0; i < 40000; i++)
{
for (int j = 0; j < 40000; j++)
{
//cout << "i = " << i << ", I am Thread " << omp_get_thread_num() << endl;
sum += 1;
}
}
}
printf("sum=%d\n", sum);
double end = clock();
printf("Running time= %f", (end - start)/CLOCKS_PER_SEC);
}
reduction(+:sum)
冒号前面的“+”表示在各线程中sum要保留数据,计算结束后一起累加。
当然,OpenMP 不止能做累加,凡是累计运算都是可以的,如下表所示:
| 操作 | 私有临时变量初值 |
|---|---|
| +、- | 0 |
| * | 1 |
| & | ~0 |
| ` | ` |
| ^ | 0 |
| && | 1(true) |
| ` |
再如,为合理管理私有数据和公有数据,private命令可以声明循环的私有变量,这些变量在各线程中互相独立,互不影响,但是要注意,private不可声明static变量;
#pragma omp parallel for private(k1,k2)
for (k1 = 1; k1 < 100; k1++)
{
for (k2 = 1; k2 < 100; k2++)
{
cout <<"k1="<< k1 << endl;
cout <<"k2="<< k2 << endl;
cout << "k=" << k << endl;
}
}